Prerequisites for MPLS Traffic Engineering—Fast Reroute
Link and Node Protection
Link and Node Protection
Your network must support the following Cisco IOS XE features:
• IP Cisco Express Forwarding
• Multiprotocol Label Switching (MPLS)
Your network must support at least one of the following protocols:
• Intermediate System-to-Intermediate System (IS-IS)
• Open Shortest Path First (OSPF)
Before configuring FRR link and node protection, it is assumed that you have done the following tasks but
you do not have to already have configured MPLS traffic engineering (TE) tunnels:
• Enabled MPLS TE on all relevant routers and interfaces
• Configured MPLS TE tunnels
and Node Protection
• Interfaces must use MPLS Global Label Allocation.
• The router’s physical interface for MPLS-TE and Fast RR for Gigabit Ethernet (GE), and Packet over
SONET (POS) is supported for enabling a 50 millisecond (ms) failover. However, the GE
subinterfaces, logical interfaces and copper interface (e.g. Fast Ethernet interface) are not supported
for enabling a 50 ms failover (even though they may be configurable). Also, FRR is not configurable
on ATM interface.
• The FRR link protect mode failover time is independent of the number of prefixes pointing to the link.
• Cisco IOS-XE does not support QoS on MPLS-TE tunnels.
• Backup tunnel headend and tailend routers must implement FRR as described in draft-pan-rsvpfastreroute-
00.txt.
• Backup tunnels are not protected. If an LSP is actively using a backup tunnel and the backup tunnel
fails, the LSP is torn down.
• LSPs that are actively using backup tunnels are not considered for promotion. If an LSP is actively
using a backup tunnel and a better backup tunnel becomes available, the active LSP is not switched to
the better backup tunnel.
• You cannot enable FRR Hellos on a router that also has Resource Reservation Protocol (RSVP)
Graceful Restart enabled.
• MPLS TE LSPs that are FRR cannot be successfully recovered if the LSPs are FRR active and the
Point of Local Repair (PLR) router experiences a stateful switchover (SSO).
Fast Reroute
Fast Reroute (FRR) is a mechanism for protecting MPLS TE LSPs from link and node failures by locally
repairing the LSPs at the point of failure, allowing data to continue to flow on them while their headend
routers attempt to establish new end-to-end LSPs to replace them. FRR locally repairs the protected LSPs
by rerouting them over backup tunnels that bypass failed links or node.
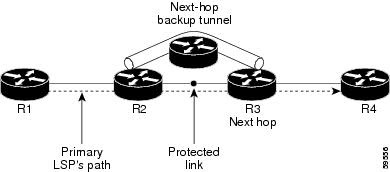
Link Protection
Backup tunnels that bypass only a single link of the LSP’s path provide link protection. They protect LSPs
if a link along their path fails by rerouting the LSP’s traffic to the next hop (bypassing the failed link).
These are referred to as next-hop (NHOP) backup tunnels because they terminate at the LSP’s next hop
beyond the point of failure. The figure below illustrates an NHOP backup tunnel.
Node Protection
FRR provides node protection for LSPs. Backup tunnels that bypass next-hop nodes along LSP paths are
called next-next-hop (NNHOP) backup tunnels because they terminate at the node following the next-hop
node of the LSP paths, thereby bypassing the next-hop node. They protect LSPs if a node along their path
fails by enabling the node upstream of the failure to reroute the LSPs and their traffic around the failed
node to the next-next hop. FRR supports the use of RSVP Hellos to accelerate the detection of node
failures. NNHOP backup tunnels also provide protection from link failures, because they bypass the failed
link and the node.
The figure below illustrates an NNHOP backup tunnel.

If an LSP is using a backup tunnel and something changes so that the LSP is no longer appropriate for the
backup tunnel, the LSP is torn down. Such changes are the following:
• Backup bandwidth of the backup tunnel is reduced.
• Backup bandwidth type of backup tunnel is changed to a type that is incompatible with the primary
LSP.
• Primary LSP is modified so that FRR is disabled. (The no mpls traffic-eng fast-reroute command is
entered.)
Bandwidth Protection
NHOP and NNHOP backup tunnels can be used to provide bandwidth protection for rerouted LSPs. This is
referred to as backup bandwidth. You can associate backup bandwidth with NHOP or NNHOP backup
tunnels. This informs the router of the amount of backup bandwidth a particular backup tunnel can protect.
When a router maps LSPs to backup tunnels, bandwidth protection ensures that an LSP uses a given
backup tunnel only if there is sufficient backup bandwidth. The router selects which LSPs use which
backup tunnels in order to provide maximum bandwidth protection. That is, the router determines the best
way to map LSPs onto backup tunnels in order to maximize the number of LSPs that can be protected. For
information about mapping tunnels and assigning backup bandwidth, see the "Backup Tunnel Selection
Procedure" section.
LSPs that have the “bandwidth protection desired” bit set have a higher right to select backup tunnels that
provide bandwidth protection; that is, those LSPs can preempt other LSPs that do not have that bit set. For
more information, see the "Prioritizing Which LSPs Obtain Backup Tunnels with Bandwidth Protection"
section.
RSVP Hello Operation
RSVP Hello enables RSVP nodes to detect when a neighboring node is not reachable. This provides nodeto-
node failure detection. When such a failure is detected, it is handled in a similar manner as a link-layer
communication failure.
RSVP Hello can be used by FRR when notification of link-layer failures is not available (for example, with
Fast Ethernet), or when the failure detection mechanisms provided by the link layer are not sufficient for
the timely detection of node failures.
A node running Hello sends a Hello Request to a neighboring node every interval. If the receiving node is
running Hello, it responds with Hello Ack. If four intervals pass and the sending node has not received an
Ack or it receives a bad message, the sending node declares that the neighbor is down and notifies FRR.
There are two configurable parameters:
• Hello interval--Use the ip rsvp signalling hello refresh interval command.
• Number of acknowledgment messages that are missed before the sending node declares that the
neighbor is down--Use the ip rsvp signalling hello refresh misses command
RSVP Hello Instance
A Hello instance implements RSVP Hello for a given router interface IP address and remote IP address. A
large number of Hello requests are sent; this puts a strain on the router resources. Therefore, create a Hello
instance only when it is necessary and delete it when it is no longer needed.
There are two types of Hello instances:
• RSVP Hello Instance,
• RSVP Hello Instance,
Active Hello Instances
If a neighbor is unreachable when an LSP is ready to be fast rerouted, an active Hello instance is needed.
Create an active Hello instance for each neighbor with at least one LSP in this state.
Active Hello instances periodically send Hello Request messages, and expect Hello Ack messages in
response. If the expected Ack message is not received, the active Hello instance declares that the neighbor
(remote IP address) is unreachable (lost). LSPs traversing that neighbor may be fast rerouted.
If there is a Hello instance with no LSPs for an unreachable neighbor, do not delete the Hello instance.
Convert the active Hello instance to a passive Hello instance because there may be an active instance on the
neighboring router that is sending Hello requests to this instance.
Passive Hello Instances
Passive Hello instances respond to Hello Request messages (sending Ack messages), but do not initiate
Hello Request messages and do not cause LSPs to be fast rerouted. A router with multiple interfaces can
run multiple Hello instances to different neighbors or to the same neighbor.
A passive Hello instance is created when a Hello Request is received from a neighbor with a source IP
address/destination IP address pair in the IP header for which a Hello instance does not exist.
Delete passive instances if no Hello messages are received for this instance within 10 minutes.
Backup Tunnel Support
Backup tunnel support has the following capabilities:
Backup Tunnels Can Terminate at the Next-Next Hop to Support FRR
Backup tunnels that terminate at the next-next hop protect both the downstream link and node. This
provides protection for link and node failures. For more detailed information, see the Node Protection,
Multiple Backup Tunnels Can Protect the Same Interface
There is no limit (except memory limitations) to the number of backup tunnels that can protect a given
interface. In many topologies, support for node protection requires supporting multiple backup tunnels per
protected interface. These backup tunnels can terminate at the same destination or at different destinations.
That is, for a given protected interface, you can configure multiple NHOP or NNHOP backup tunnels. This
allows redundancy and load balancing.
In addition to being required for node protection, the protection of an interface by multiple backup tunnels
provides the following benefits:
• Redundancy--If one backup tunnel is down, other backup tunnels protect LSPs.
• Increased backup capacity--If the protected interface is a high-capacity link and no single backup path
exists with an equal capacity, multiple backup tunnels can protect that one high-capacity link. The
LSPs using this link will fail over to different backup tunnels, allowing all of the LSPs to have
adequate bandwidth protection during failure (rerouting). If bandwidth protection is not desired, the
router spreads LSPs across all available backup tunnels (that is, there is load balancing across backup
tunnels). For a more detailed explanation, see the Backup Tunnel Selection Procedure,
Backup Tunnels Provide Scalability
A backup tunnel can protect multiple LSPs. Furthermore, a backup tunnel can protect multiple interfaces.
This is called many-to-one (N:1) protection. An example of N:1 protection is when one backup tunnel
protects 5000 LSPs, each router along the backup path maintains one additional tunnel.
One-to-one protection is when a separate backup tunnel must be used for each LSP needing protection. N:1
protection has significant scalability advantages over one-to-one (1:1) protection. An example of 1:1
protection is when 5000 backup tunnels protect 5000 LSPs, each router along the backup path must
maintain state for an additional 5000 tunnels.
No comments:
Post a Comment